

K8s主备高可用集群架构方案
K8s 主备高可用集群架构方案
Kuberneter 主备模式高可用集群架构图
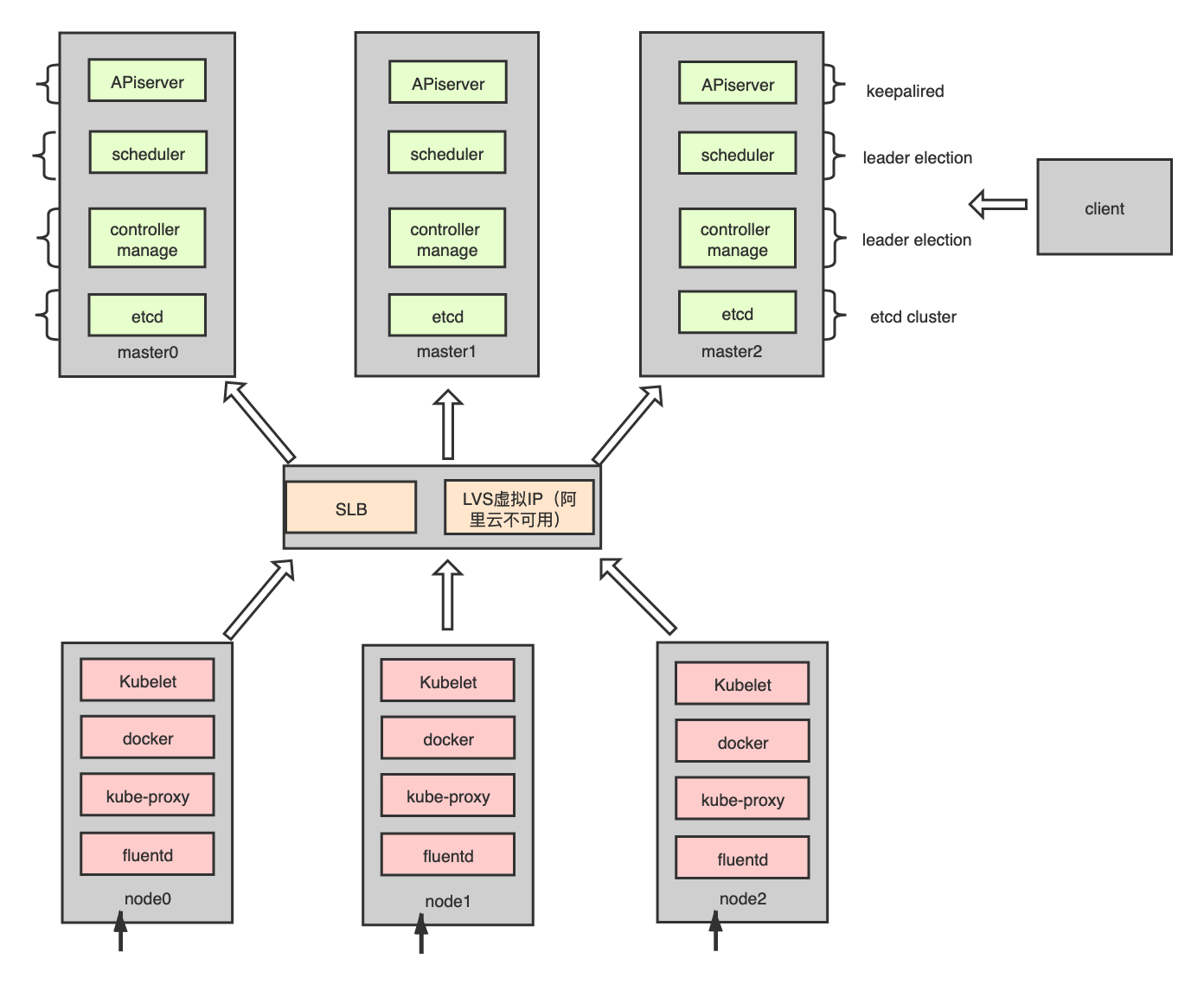
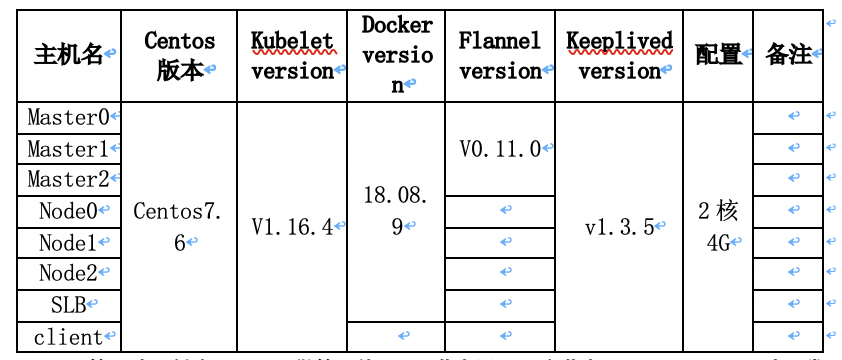
一 节点规划
Master管理端不创建pod,只做管理使用。3节点需要2个节点可用,api-server才正常工作。
总计需求7台,监控1台,日志1台暂未加入。
二 主备模式高可用架构说明
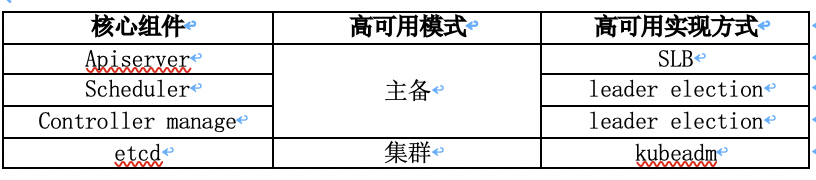
1 api-server
简介:系统管理指令的统一入口,任何对资源进行增删改查的操作都要交给APIServer处理后再提交给etcd。
实现:SLB负载均衡(实体机通过keepalived实现高可用,当某个节点故障时触发keepalived vip 转移);
2 controller-manager
简介:负责管理控制器,比喻apiserver是“前台”,controller-manager是“后台“
实现:k8s内部通过选举方式产生领导者(由–leader-elect 选型控制,默认为true),同一时刻集群内只有一个controller-manager组件运行;
3 scheduler
简介:调度pod到合适node,
实现:k8s内部通过选举方式产生领导者(由–leader-elect 选型控制,默认为true),同一时刻集群内只有一个scheduler组件运行;
4 etcd
简介:高可用的键值存储系统,存储各资源状态
实现:通过运行kubeadm方式自动创建集群来实现高可用,部署的节点数为奇数,3节点方式最多容忍一台机器宕机。
三 监控系统
1 Zabbix
通过每台服务器安装zabbix-agentd发送到服务器端,需编写自定义模版。
2 prometheus 原生组件
(node-exporter、prometheus、grafana对集群进行监控。)
3 Prometheus **主服务,用来抓取和存储时序数据
4 client library **用来构造应用或 exporter 代码 (go,java,python,ruby)
push 网关可用来支持短连接任务
5 可视化的dashboard
(两种选择,promdash 和 grafana.目前主流选择是 grafana.)
一些特殊需求的数据出口(用于HAProxy, StatsD, Graphite等服务)
实验性的报警管理端(alartmanager,单独进行报警汇总,分发,屏蔽等 )
四 日志系统
1 ELK+filebeat -node级日志
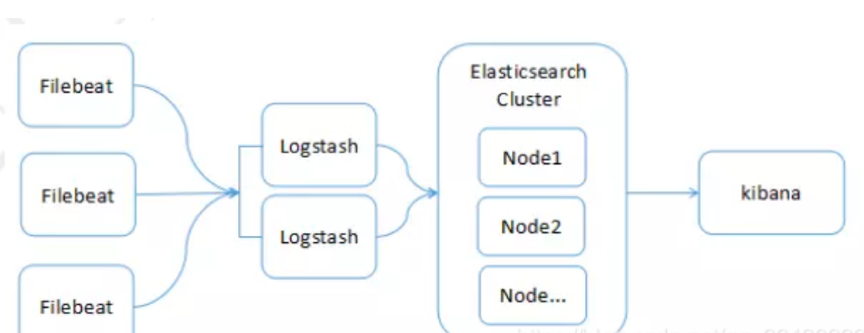
Elk架构图
- 多个Filebeat在各个业务端进行日志采集,然后上传至Logstash
- 多个Logstash节点并行(负载均衡,不作为集群),对日志记录进行过滤处理,然后上传至Elasticsearch集群
- 多个Elasticsearch构成集群服务,提供日志的索引和存储能力
- Kibana负责对Elasticsearch中的日志数据进行检索、分析根据业务特点,还可以加入某些中间件,如Redis、Kafak等
2node级日志
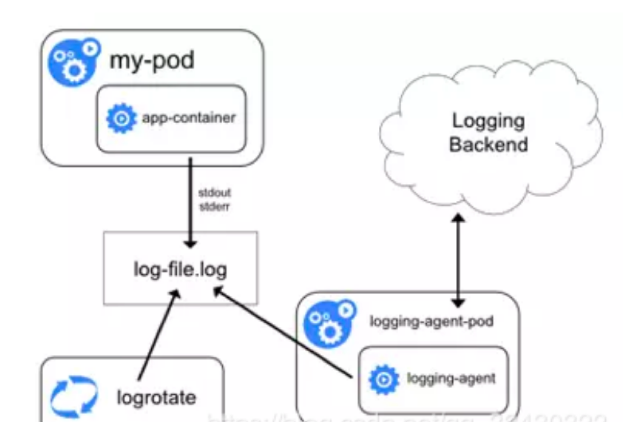
每个节点标准输出到写入主机绝对路径。node上各运行一个日志代理容器,对本节点/var/log和 /var/lib/docker/containers/两个目录下的日志进行采集,然后汇总到elasticsearch集群,最后通过kibana展示。
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
