
服务可用性思考
运维稳定性体系建设
- [运维稳定性体系建设](https://47.107.234.86/docs/guanlizhidu/guanlizhidu-1dpnaq0hu0a1p#bevhl)
- [关键4个指标](https://47.107.234.86/docs/guanlizhidu/guanlizhidu-1dpnaq0hu0a1p#a1x7jk)
### 关键4个指标
运维准入性规范:流程规范
- 功能测试-QA人员
- 性能测试-QA人员(容量和资源对应使用水平)
- 安全测试-安全人员
- 稳定性测试-运维人员-准入性测试(cpu,内存,微服务down,数据库,中间件)
(Robust)鲁棒性:亦称健壮性、稳健性、强健性,是系统的健壮性,它是在异常和危险情况下系统生存的关键,是指系统在一定(结构、大小)的参数摄动下,维持某些性能的特性。比如说,计算机软件在`输入错误、磁盘故障、网络过载`或有意攻击情况下,能否`不死机、不崩溃`,就是该软件的鲁棒性。
1 服务可用性怎么来的
服务可⽤性的⼀知半解谈到⾼并发和⾼可⽤往往引起很多⼈的兴趣,有时候成为框架选择的噱头。实际上,它们往往和框架关系不⼤,⽽是跟架构息息相关。在很多时候,⽼码农会直⾯⼀个问题:“系统的服务可⽤性是多少?是怎么得来?”
但在思考这个问题之前,先要澄清⼀个概念,那就是——
1.1 什么是服务可⽤性可⽤性

就是⼀个系统处在可⼯作状态的时间的⽐例,这通常被描述为任务可⾏率。
数学上来讲,相当于1减去不可⽤性。——wiki百科相应的,
我们的软件系统处于可⼯作的时间⽐例,就是服务的可⽤性,也就是说,服务可⽤性可以描述为⼀个百分⽐的数值。
1.2 SLO(service-level objective,服务级⽬标)
我们经常⽤这个SLO(service-level objective,服务级⽬标)来代表服务可⽤性,⾄于SLO,SLA,SLI等概念之间的差异,这⾥暂不做深⼊讨论。
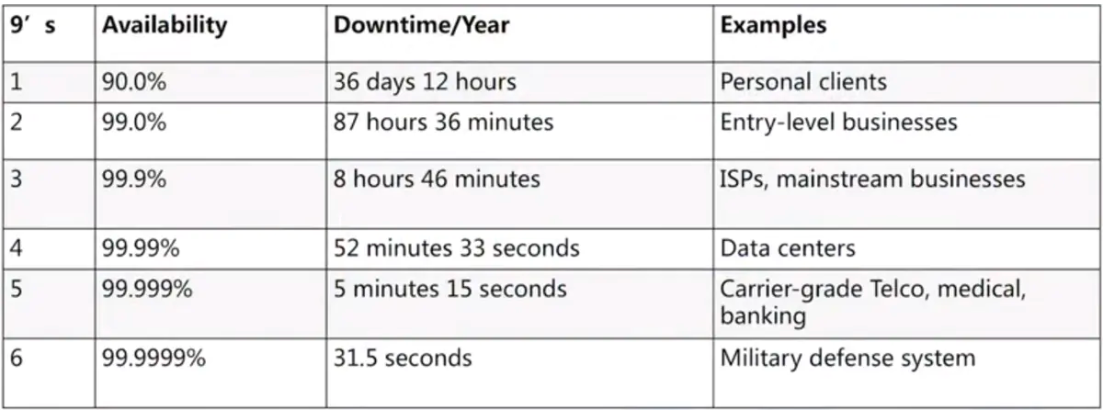
SLO⽤数字来定义可⽤性对于特定服务的意义,来表⽰服务⼏乎总是活着,总是处于可以快速运⾏的状态。制定SLO是根据如下:
```yaml
服务总时长 / (服务总时长 + 服务总中断时长) * 100%
一年是525600分钟
一天是1440分钟(假如中断时长合计是一天)
525600/(525600+1440)*100%=99.73%
```
绝⼤多数软件服务和系统的⽬标应该是近乎完美的可⽤性,⽽不是完美的可⽤性。服务可⽤性⼀般是99.999%或99.99%,⽽不是100%,因为⽤户⽆法区分服务是100%可⽤和不“完美”可⽤之间的区别。在⽤户和服务之间还有许多其他的系统,例如笔记本电脑、家庭WiFi、互联⽹等等,这些系统的可⽤性远远低于100%。因此,99.99%和100%之间的边际差异在其他不可⽤性的噪⾳中丢失了,并且,即使为增加最后⼀部分可⽤性付出了巨⼤努⼒,⽤户也可能没有从中获得任何好处。
很多云服务的⽬标是向⽤户提供99.99%的可⽤性(就是我们常说的“四个9”)。
⼀些服务在外部承诺较低的数字,但在内部可能设定了99.99%的⽬标。作为SLA,这个严格的⽬标描述了⽤户在违反合同之前对服务性能不满意的情况,因为软件服务的⾸要⽬标是让⽤户满意。对于许多服务,99.99%的内部⽬标代表了平衡成本、复杂性和可⽤性的最佳位置。
1.3 服务可⽤性解读
服务可⽤性是中断频率和持续时间的函数。它是通过以下⽅式衡量的:*停机频率,或者是它的倒数: MTTF (平均停机时间)。*持续时间,使⽤MTTR (平均修复时间)。持续时间根据⽤户的经历定义:从故障开始持续到正常⾏为恢复。因此,可⽤性在数学上定义为使⽤适当单位的MTTF / (MTTF + MTTR)
因此,可⽤性在数学上定义为使⽤适当单位的MTTF / (MTTF + MTTR)。
1.4 关键依赖
服务的可⽤性不能超过其所有关键依赖关系的交集。如果服务的⽬标是提供99.99%的可⽤性,那么所有的关键依赖项必须远远超过99.99%的可⽤性。据说在⾕歌内部,使⽤这样⼀个经验法则:因为任何服务都有⼏个关键依赖项,以及⾃⾝的特殊问题,关键依赖必须提供⼀个与服务相关的额外9%的可⽤性(这⾥为99.999%)。
如果有⼀个关键依赖,⼀个相对常见的挑战是没有提供⾜够的可⽤性,就必须采取措施来增加依赖项的有效可⽤性(例如,通过缓存、限流、优雅降级等等)。
1.5 降低期望
从数学上看,服务的可⽤性不能超过其事件频率乘以其检测和恢复时间。例如,每年有4次完全宕机,每次持续15分钟,结果总共是60分钟。即使该服务在这⼀年中剩下的时间⾥都运⾏良好,99.99%的可⽤性(每年停机时间不超过53分钟)也是没有达的。如果服务被依赖于⽆法提供相应⽔平的可⽤性级别,那么就应该努⼒纠正这种情况,可以通过增加⾃⾝服务的可⽤性等级,或者如前所述的增加缓解措施。降低期望值(即公布的可⽤性)也是⼀种选择,⽽且往往是正确的选择:向相关服务明确表⽰,它应该重新设计系统以弥补我们服务可⽤性,或者降低⾃⼰的⽬标。如果不纠正或解决这种差异,可⽤性将⽆法达到要求。
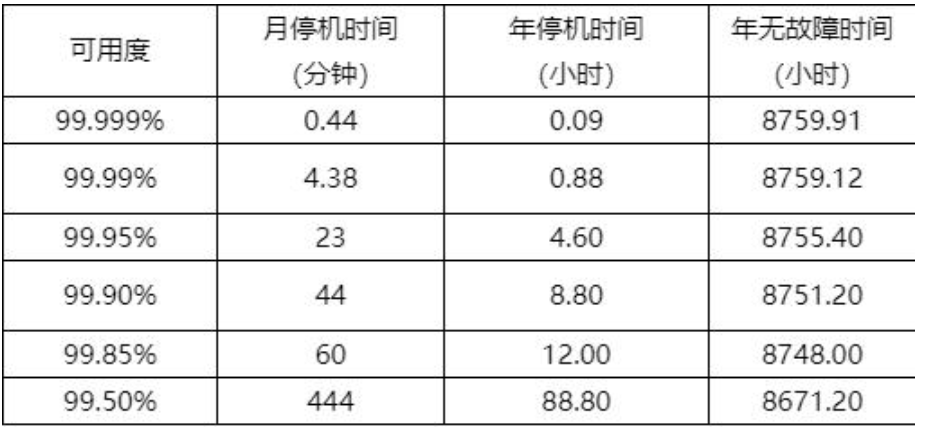
1.6 服务可⽤性的计算
考虑⼀个⽬标可⽤性为99.99%的⽰例服务,并处理依赖项和停机响应的需求。
1.6.1 ⼀个例⼦
假设这个99.99%的可⽤服务具有以下特征:
- •每年⼀次⼤停机和三次⼩停机。这些数字听起来很⾼,但是99.99%的可⽤性⽬标确实意味着每年有20到30分钟的⼤范围停机和⼏次短暂的部分停机。这⾥的假设是:单个分⽚的失败并不被认为是整个系统的失败,总体可⽤性是根据分⽚可⽤性的加权和来计算的。
- •有五个独⽴关键依赖,服务可⽤性为99.999%。
- •这五个相互独⽴的碎⽚,不能相互转移。
- •所有变更逐个进⾏,每次⼀个分⽚。
那么,本年度服务中断的总预算为每年525,600分钟的的0.01%或53分钟(以每年365天为基础)。分配给关键依赖的服务中断预算是5个525,600分钟的0.001%,即525,600分钟的0.005%或26分钟。考虑到关键依赖的服务中断,该服务的中断时间预算为53-26=27分钟。
进⼀步,预计停机次数为4次(1次完全停机,3次停机仅影响⼀个分⽚),预期服务中断的总影响:(1x100%)+(3x20%)=1.6。
那么,可⽤于检测和从中断恢复的时间为27/1.6=17分钟。如果监控和告警的时间是2分钟,值班⼈员调查警报的时间为5分钟的话,则有效解决问题的剩余时间是10分钟。提⾼可⽤性的⽅向仔细研究这些数字,
1.7 有三个主要的因素可以使服务更可靠。
- •透过流程、测试、设计review等⼿段,减少宕机的次数。
- •通过分⽚、地理隔离、优雅降级或客户隔离,缩⼩停机范围。
- •缩短恢复时间ーー透过监控、⼀键式回滚等。可以在这三个⽅向之间进⾏权衡,以便实现更加容易。
例如,如果17分钟的MTTR很难实现,那么应该将精⼒集中在减少平均停⽤的范围上。
1.8 服务可⽤性之依赖嵌套
⼀个不经意的推断,依赖链中的每个额外链接都需要增加额外的可⽤性等级么?
例如,
- ⼆级依赖需要两个额外的9,
- 三级依赖需要三个额外的9,
- 以此类推。这种推论是不正确的,
它基于依赖关系层次结构,即在每个级别上具有常量扇出的树具有许多独⽴关键依赖的⾼可⽤性服务系统显然是不现实的。
⽆论在依赖项树中出现在哪⾥,关键依赖项本⾝都可能导致整个服务(或服务分⽚)失败。
因此,如果给定的组件A表现为⼏个服务的依赖项,那么A应该只计算⼀次,因为⽆论有多少中间的服务受到影响,A的故障终将导致服务的故障。
1.7.1 正确的依赖计算可能是这样的:
•如果⼀个服务具有N个唯⼀的关键依赖项,那么每个依赖对服务导致的不可⽤性贡献1/N,⽽不管它在层次结构中的深度如何。
•即使它在依赖项层次结构中出现多次,每个依赖也只计算⼀次。
例如,假设服务b的故障预算为0.01%。服务拥有者愿意花⼀半的预算在他们⾃⼰的bug和损失上,另⼀半花在关键依赖上。如果服务有N个这样的依赖项,每个依赖项接收剩余故障预算的1/N。典型的服务通常有5到10个关键依赖项,因此每个服务的失败率只有服务b的⼗分之⼀或⼆⼗分之⼀。因此,根据⼀般经验,服务的关键依赖项必须增加额外的可⽤性。
1.9 服务可⽤性之故障预算
⼀般地,使⽤故障预算来平衡可⽤性和创新速度。这个预算定义了在⼀段时间内(通常是⼀个⽉)服务可接受的故障⽔平。故障预算只是1减去服务的SLO,因此,99.99%可⽤的服务是故障为0.01%的“预算”。只要服务没有花费当⽉的故障预算,开发团队就可以在合理范围内⾃由地发布新特性、更新等等。如果使⽤了故障预算,除了紧急安全修复和解决最初导致违规的更改之外,服务可能将冻结变更。直到服务在预算中赢得了空间,或者时间重置。使⽤SLOs滑动窗⼝,因此故障预算逐渐增加。对于SLO⼤于99.99%的成熟服务,每季度重置预算是适当的,因为允许的停机时间很⼩。故障预算提供了⼀个共同的、数据驱动的机制来评估发布风险,从⽽消除了可能在运维团队和产品开发团队之间产⽣的结构性紧张。故障预算还提供了⼀个共同的⽬标,在不“超出预算”的情况下实现更快的创新和更多的发布。
1.20 提⾼服务可⽤性:减少关键依赖
现在,可以重点讨论服务的依赖关系,如何进⾏设计以减少并最⼩化关键依赖。
1.21 关于关键依赖
⼀般的,任何关键部件的可⽤性必须是整个系统⽬标的10倍。因此,在⼀个理想的世界中,⽬标是使尽可能多的组件成为⾮依赖的。这样做意味着组件可以坚持较低的可靠性标准,获得创新和承担风险的⾃由。
减少关键依赖性的最基本和最明显的策略是尽可能消除SPOFs (单点故障)。较⼤的系统应该能够在没有任何⾮关键依赖项或SPOF的给定组件的情况下可以可接受地运⾏。
实际上,您可能⽆法摆脱所有关键的依赖关系,但是您可以遵循⼀些围绕系统设计的最佳实践来优化可靠性。虽然这样做并不总是可⾏的,但是如果你在设计和规划阶段计划可靠性,⽽不是在系统运⾏并影响实际⽤户之后,那么实现系统可靠性就会更容易和更有效。
当考虑⼀个新的系统或服务时,当重构或改进⼀个现有系统或服务时,⼀个架构/设计评审可以识别出内部与外部的依赖。如果服务使⽤的是共享基础设施(例如,多个⽤户可见产品使⽤的基础数据库服务),要考虑该基础设施是否得到正确使⽤。明确地将共享基础结构的所有者确定为附加的利益相关者。另外,要注意不要让依赖关系超载,⼩⼼地与这些依赖关系的所有者协调⼯作。
有时,产品或服务取决于公司⽆法控制的因素,例如,代码库、第三⽅提供的服务或数据,要识别这些因素可以减少它们带来的不可预测性。@擒龙绿旋13们带来的不可预测性。
2 冗余和隔离
通过将依赖设计为具有多个独⽴实例来减轻对关键依赖的依赖。例如,如果在⼀个实例中存储的数据提供了该数据99.9%的可⽤性,那么在三个分布的实例中存储三个副本提供了9个9的理论可⽤性级别。
在现实世界中,相关性永远不会为零,因此实际可⽤性不会接近9个9,⽽是远远⾼于3个9。如果⼀个系统或服务是“⼴泛分布的”,地理上的分离并不总是不相关的。在邻近地点使⽤多个系统,可能⽐在较远地点使⽤同⼀个系统更好。
类似地,向⼀个集群中的⼀个服务器池发送RPC可以提供99.9%的可⽤性,但是向三个不同的服务器池发送三个并发RPC并接受到达的第⼀个响应,这样有助于将可⽤性提⾼到远远超过三个9的级别。如果服务器池与RPC发送⽅的距离⼤致相等,那么这种策略还可以减少延迟。
3 故障切换与回滚
⼀个的基本经验是,当必须⼈⼯在线引发故障切换时,可能已经超出了故障预算。最好进⾏故障的安全切换,如果出现问题,这些软件可以⾃动隔离。在⽆法实现的情况下,可以执⾏⾃动脚本。同样,如果问题依赖于某⼀个⼈来检查,那么满⾜SLO的机会会很⼩。
将⼈引⼊缓解计划⼤⼤增加了SLO的风险,需要构建⽅便、快速⽽可靠回滚的系统。随着系统逐渐成熟,并且对检测问题的监视获得了信⼼,就可以通过设计系统⾃动触发安全回滚来降低MTTR。
在可能的情况下,将依赖项设计为异步的,⽽不是同步的,这样它们就不会意外地变得⾮常重要。如果服务等待来⾃其⾮关键依赖项之⼀的RPC响应,并且该依赖项的延迟会⼤⼤增加,那么这种延迟将不必要地影响⽗服务的延迟。通过将RPC调⽤设置为⾮关键的异步依赖项,可以将⽗服务的延迟与依赖项的延迟解耦。虽然异步性可能会使代码和基础结构复杂化,但这种权衡可能是值得的。检查所有可能的失效模式检查每个组件和依赖项,并确定其故障的影响。
3.1 以下问题可能是⼀些⽅向:
- •如果其中⼀个依赖项失败,服务能否继续以降级模式提供服务?换句话说,为优雅的降级⽽设计。
- •如何处理在不同情况下依赖项不可⽤的问题?在服务启动时?在运⾏期间?设计和实现⼀个健壮的测试环境,确保每个依赖项都有⾃⼰的测试覆盖率,并且使⽤专门针对环境的⽤例进⾏测试。
3.2 以下是⼀些推荐的测试策略:
- •使⽤集成测试执⾏故障注⼊ーー验证系统能否在任何依赖关系发⽣故障时幸存下来。
- •进⾏灾难测试以识别弱点或隐藏的依赖关系。记录后续⾏动,以纠正发现的bug。
- •故意让系统过载,看看它是如何退化的。⽆论如何,系统对负载的响应都将被测试;最好是⾃⼰执⾏这些测试,⽽不是将负载测试留给⽤户。
4 容量规划
确保每个依赖项都得到了正确的供给,如果成本可以接受,就过度供给。如果可能,将依赖项的配置标准化,以限制⼦系统之间的不⼀致性,并避免⼀次性的故障模式。
检测、故障排除和诊断问题要尽可能简单,有效的监测是能够及时发现问题的关键组成部分。诊断具有严重依赖关系的系统是困难的,但总是有⼀个不需要操作员就可以减轻故障的⽅案。期待随着规模⽽来的变化,当在⼀台机器上以⼆进制⽂件开始的服务在更⼤的规模上部署时,可能会有许多明显或不明显的依赖关系。每⼀个规模的数量级都会暴露出新的瓶颈,不仅仅是⾃⼰服务,还有所依赖的服务。
考虑⼀下,如果依赖项不能像所需要的那样快速扩展,将会发⽣什么。还要注意,系统依赖关系会随着时间的推移⽽发展,并且依赖关系的列表可能会随着时间的推移⽽增长。在基础设施⽅⾯,⼀个典型的设计是建⽴⼀个不需要重⼤变更就可以扩展到初始⽬标负载10倍的系统。
,⼀个典型的设计是建⽴⼀个不需要重⼤变更就可以扩展到初始⽬标负载10倍的系统。
5 结束语
服务的⽤性并不⾼深莫测,它只是⼀个百分⽐的数字。服务可⽤性的指标(例如99.99%)往往令⼈不安,但并⾮不可实现。提供超过四个9的服务可⽤性,不是通过超出常⼈的智慧,⽽是通过不断地完善规则形成最佳实践,并且全⾯应⽤
- 感谢你赐予我前进的力量
-
 微信
微信  支付宝
支付宝
